FTensor
FTensor is a C++ library that simplifies the construction of codes that use tensors.
Motivation
As a simple example, consider multiplying a vector $P$ by a matrix $T$ and putting the results into $Q$.
$$(\table Q_x; Q_y) = (\table T_{xx}, T_{xy}; T_{yx}, T_{yy}) (\table P_x; P_y)$$Alternately, you can write it as
$$\table Q_x= ∑↙{j=x,y} T_{xj} P_j; Q_y= ∑↙{j=x,y} T_{yj} P_j$$or even more simply as
$$Q_i= ∑↙{j=x,y} T_{ij} P_j$$where the index $i$ is understood to stand for $x$ and $y$ in turn.
Einstein introduced the convention that if an index appears in two tensors that multiply each other, then that index is implicitly summed. This mostly removes the need to write the summation symbol ∑. Using this Einstein summation notation, the matrix-vector multiplication becomes simply
$$Q_i = T_{ij} P_j$$Of course, now that the notation has become so nice and compact, it becomes easy to write much more complicated formulas such as the definition of the Riemann tensor
$$R^{i}_{jkl} = dG^{i}_{jkl} − dG^{i}_{lkj} + G^{m}_{jk} G^{i}_{ml} − G^{m}_{lk} G^{i}_{jm}$$To express this in code with regular C arrays, we could use multidimensional arrays and start writing loops
for(int i=0;i<3;++i)
for(int j=0;j<3;++j)
for(int k=0;k<3;++k)
for(int l=0;l<3;++l)
{
R[i][j][k][l]=
dG[i][j][k][l] - dG[i][l][k][j];
for(int m=0;m<3;++m)
R[i][j][k][l]+=G[m][j][k]*G[i][m][l]
- G[m][l][k]*G[i][m][j];
}
This is a dull, mechanical, error-prone task, exactly the type of task that we want computers to do for us. This style of programming is often referred to as C-tran, since it is programming in C++ but with all of the limitations of Fortran 77. Moreover, the Riemann tensor has a number of symmetries which reduces the total number of independent components from 81 to 6. So this simple loop does 10 times more work than needed.
What we would like is to write this as
R(i,j,k,l)=dG(i,j,k,l) - dG(i,l,k,j)
+ G(m,j,k)*G(i,m,l) - G(m,l,k)*G(i,m,j);
and have the computer do all of the summing automatically.
There are a number of libraries with varying degrees of support for this notation. Most of them only provide vectors and matrices, but not higher rank tensors with symmetry properties. Of those that do provide these higher rank tensors, they produce slow, inefficient code. The one exception is LTensor which was directly inspired by FTensor.
Benchmarks
FTensor achieves high performance by using expression templates. If you are interested in all of the gory details, you can read the paper. In essence, expression templates allows the compiler to unroll the expressions at compile-time ... in theory. In practice, the compiler may not be able to simplify the expressions, and performance can get much worse.
For example, consider the infinite sum
$$\table y_i = y_i , + a_i ∑↙{n=0}↖\∞ {0.1}^n ; , + 2·b_i ∑↙{n=0}↖\∞ ({0.1·0.2})^n ; , + 3(a_j b_j) c_i ∑↙{n=0}↖\∞ ({0.1·0.2·0.3})^n ; , + 4(a_j c_j)(b_k b_k) d_i ∑↙{n=0}↖\∞ ({0.1·0.2·0.3·0.4})^n… ;$$where we can keep adding terms on the right to make the expression more complicated. We implement this using FTensor
Tensor1<double,3> y(0,1,2);
Tensor1<double,3> a(2,3,4);
Tensor1<double,3> b(5,6,7);
Tensor1<double,3> c(8,9,10);
Tensor1<double,3> d(11,12,13);
...
const Index<'i',3> i;
const Index<'j',3> j;
const Index<'k',3> k;
...
for(int n=0;n<10000000;++n)
{
y(i)+=a(i)
+ 2*b(i)
+ 3*(a(j)*b(j))*c(i)
+ 4*(a(j)*c(j))*(b(j)*b(j))*d(i)
...
;
a(i)*=0.1;
b(i)*=0.2;
c(i)*=0.3;
d(i)*=0.4;
...
}
and compare it to an implementation with a C-tran version. In 2003, I ran the benchmarks with a number of different compilers on different chips and operating systems (click on the image for a larger version).
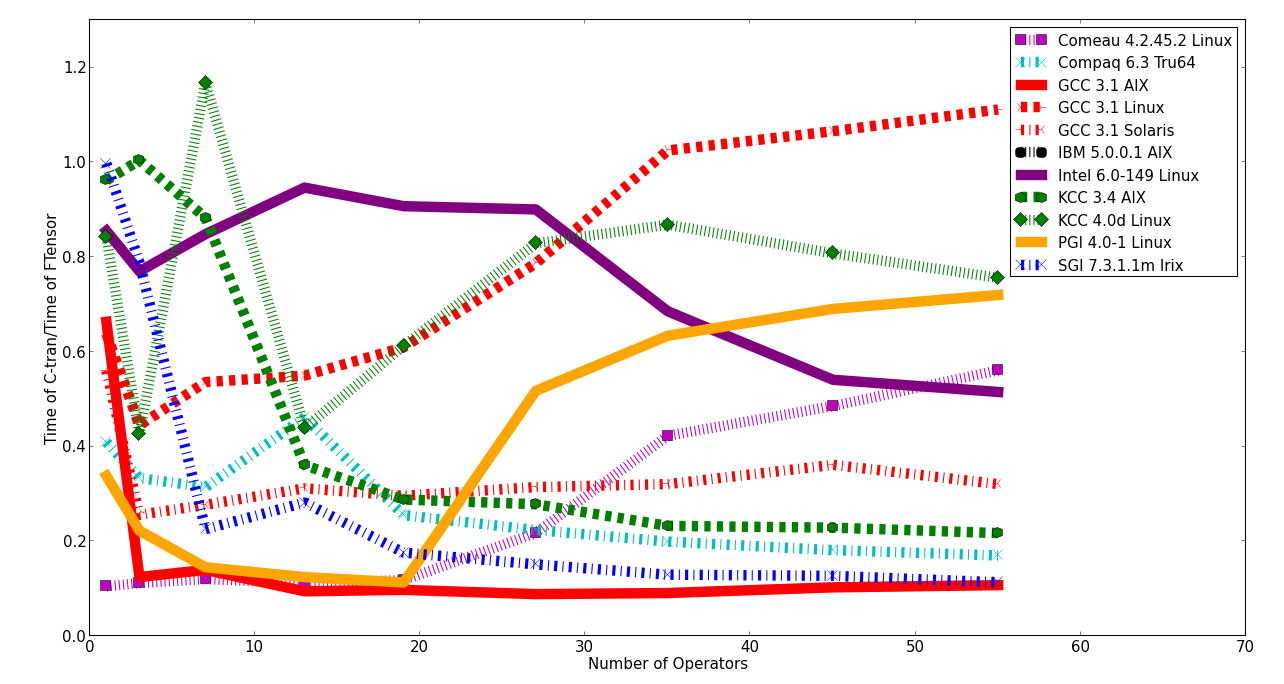
This shows the relative speed of the C-tran and FTensor versions versus the number of operators (+ or *) in the expression. Any points less than one means that the FTensor version is slower than the C-tran version. As you can see, all of the compilers struggled to optimize the FTensor code. For all of the details on compiler versions and options, see the paper.
Moving forward a decade, we run the same benchmarks with new compilers and see what has changed.
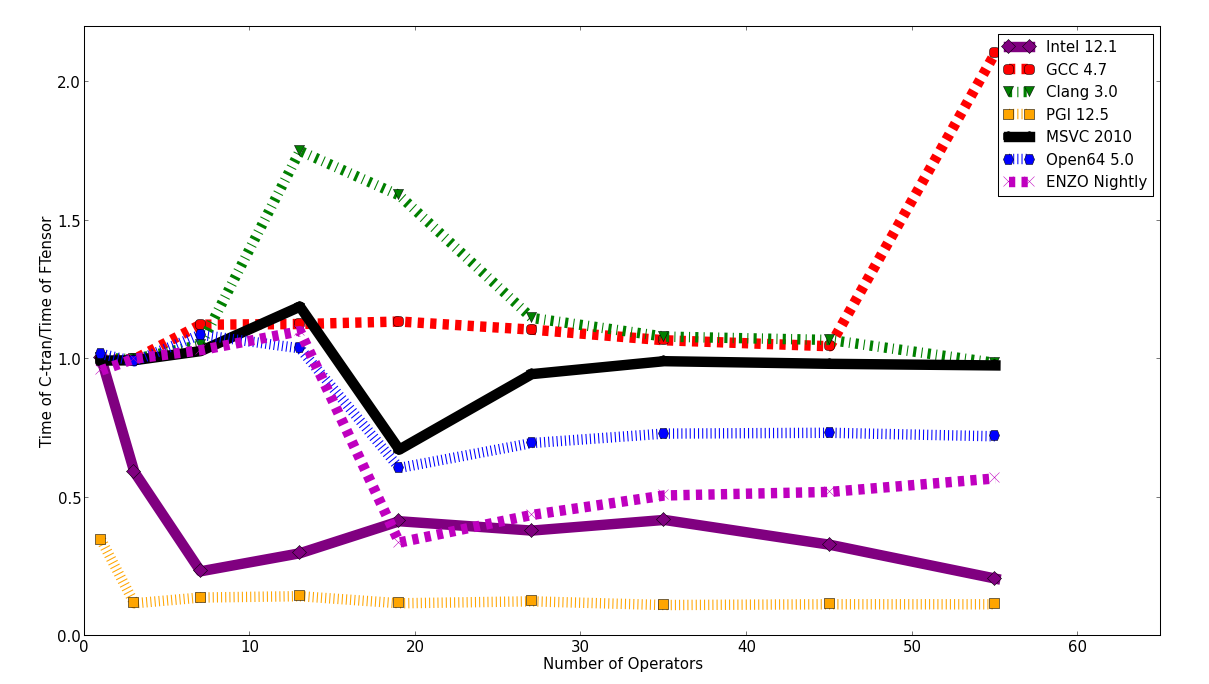
This plot shows a few interesting features.
- The FTensor code generated by the Intel and PGI compilers is generally slower than their C-tran code. This is similar to the performance from 2003.
- In contrast, the FTensor code generated by the GCC and Clang compilers is generally faster than their C-tran code. It is more efficient to use FTensor, with all of its abstractions, than it is to write the loops yourself.
So if you are committed to using one of these compilers, then it becomes more clear whether using FTensor will be a performance burden. However, that burden may arise because the compiler is really, really good at optimizing C-tran, but just as good as any other compiler at optimizing FTensor. So let's look at the speed of the C-tran versions normalized by the speed of the Intel C-tran.
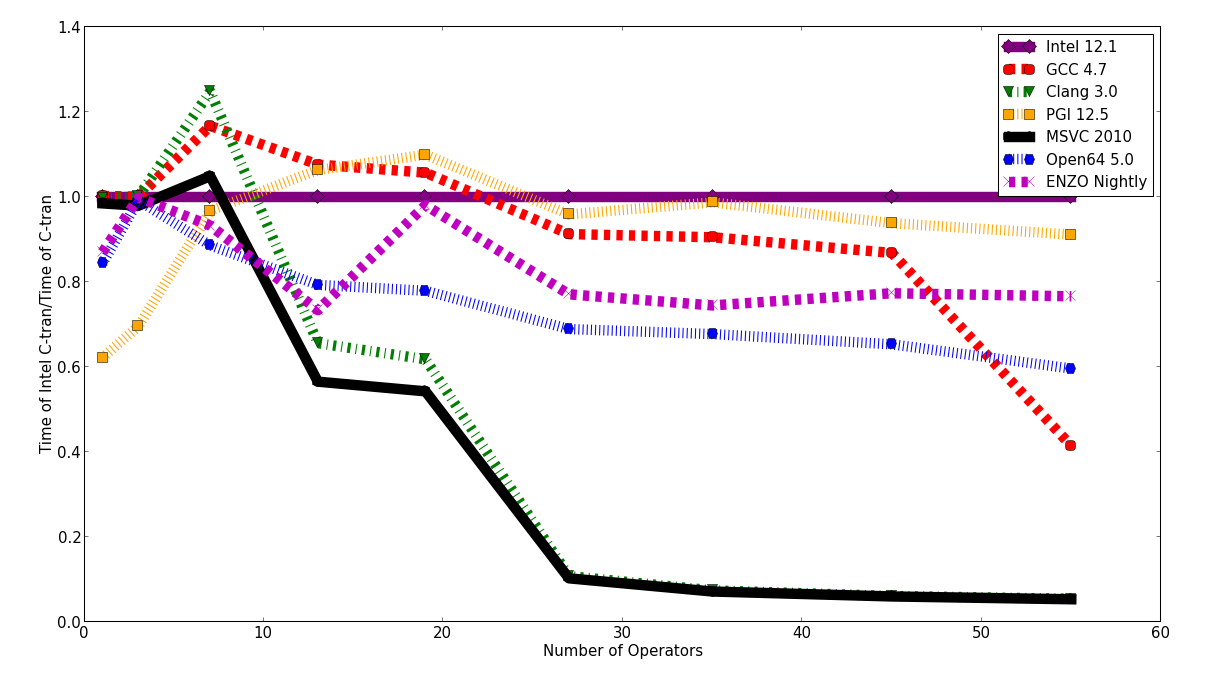
For the most complicated expression, Clang and MSVC are 20 times slower than Intel and PGI. Open64 and Pathscale's ENZO are slower, but not by such a huge fraction. Intel, GCC and PGI are reasonably competitive with each other. Now lets look at the relative speed of the FTensor versions.
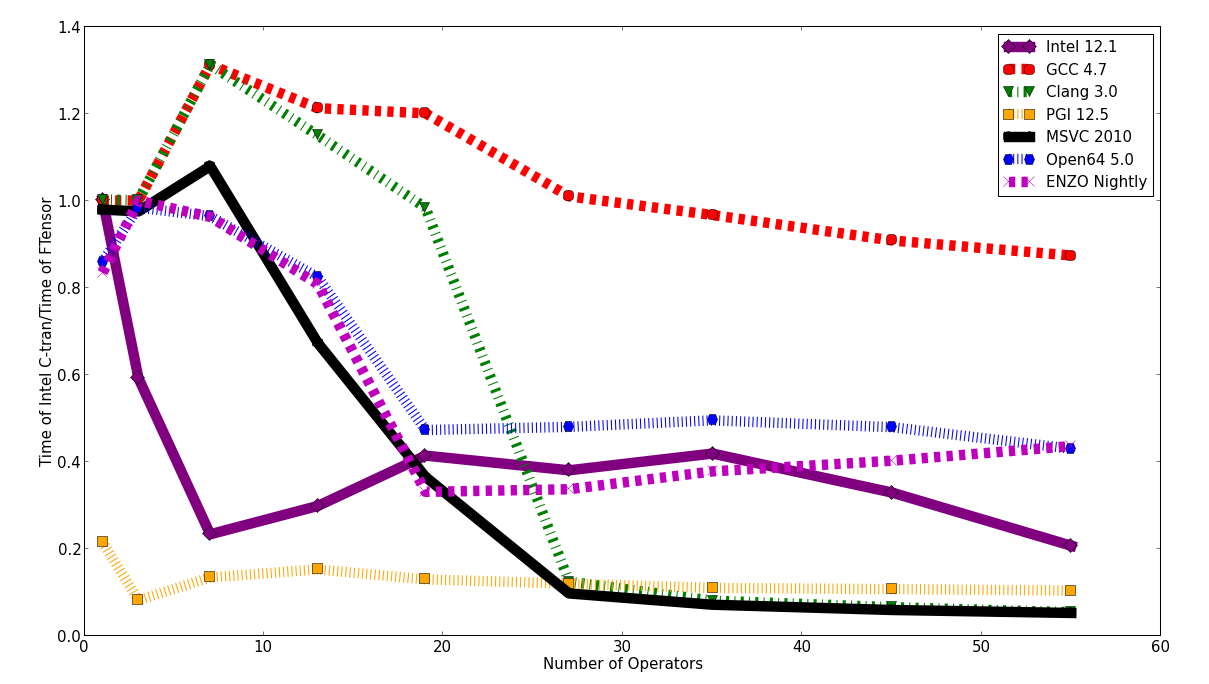
There is a clear winner here. If you want the fastest FTensor performance, use GCC.
Profile Guided Optimization
The results above used standard optimization switches. It is also possible to use profile guided optimization (PGO) to further improve performance. PGO can be a little tricky to use. The Open64 compiler produced training executables that were so slow (at least 100 times slower) that PGO was impractical. Intel's training executables were "only" 20 times slower. GCC's implementation was the most practical, with executables that were about 2 times slower. For the others, it is not clear whether Clang has implemented PGO, ENZO's PGO was not working in the version I had, the free Microsoft compiler does not ship with PGO, and my PGI license expired before I could test PGO.
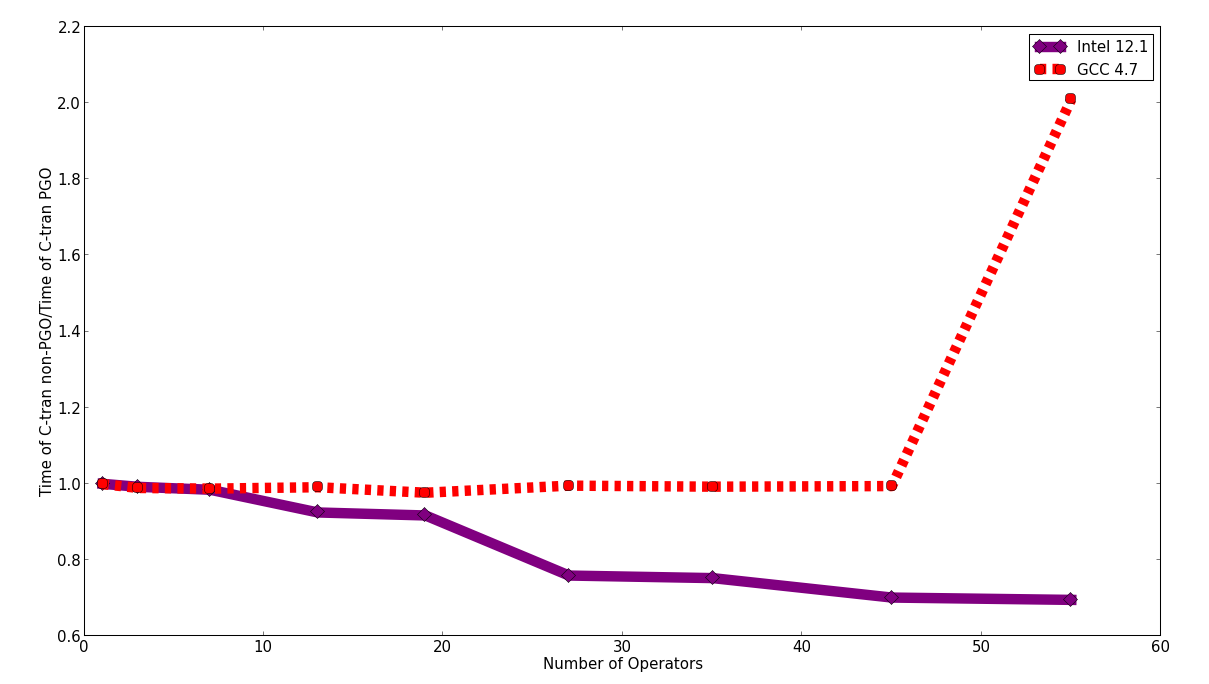
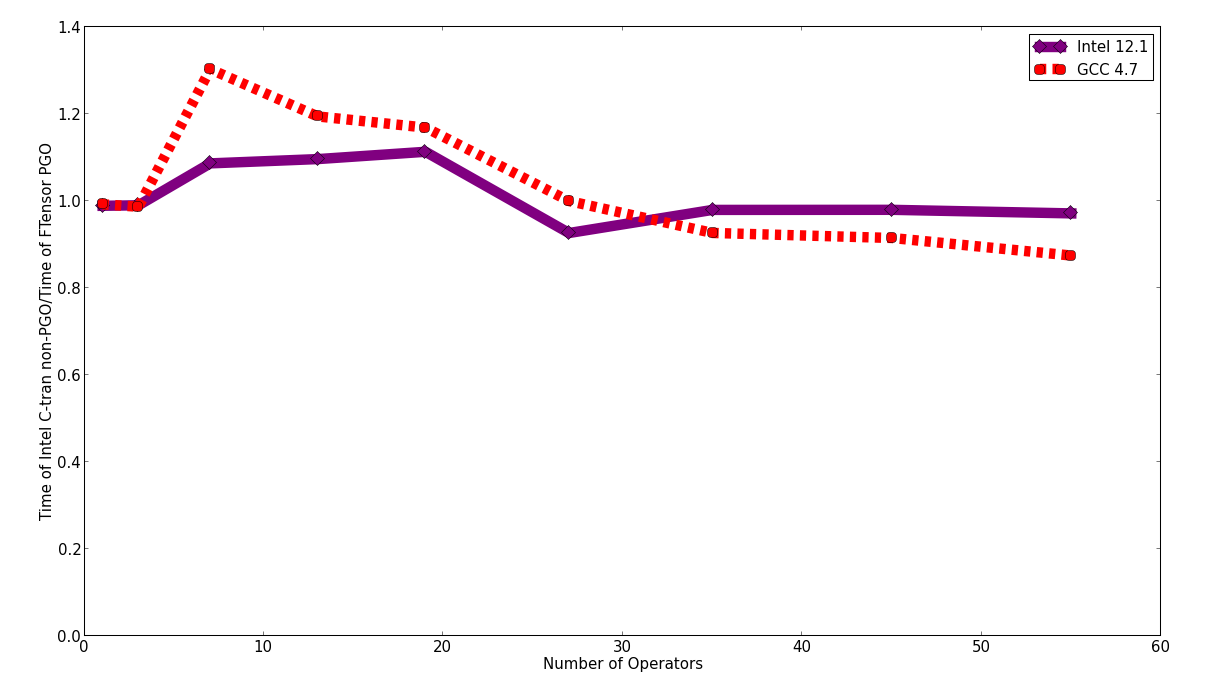
Comparing the performance of the PGO versus non-PGO results, the results are mixed. The Intel C-tran performance is always worse, but the Intel FTensor performance is always better. In fact, it is better than the Intel C-tran PGO performance and became comparable to the Intel C-tran non-PGO performance.
GCC, on the other hand, only shows an improvement with the most complicated C-tran expression, and the GCC FTensor performance is essentially unchanged.
End Note
If you want to reproduce the results here, download the code from the Mercurial repository and
read the instructions in tests/README. For the curious,
you can also look at the compiler
options.
There has been a little discussion of these benchmarks on the GCC, Clang, and Open64 mailing lists